검색 기능을 위한 Elasticsearch 개념 및 data modeling 기법 소개
Elasticsearch는 분산형 RESTful 검색 및 분석 엔진이다. 빠르고 효율적인 분산처리를 통해 얻은 검색 및 분석 결과를 REST API 형태로 제공하는 기술이라고 이해할 수 있다. Apache Lucene 기반의 Java 오픈소스이며, 사용이 간단하면서도 파워풀한 검색 성능을 보여주기 때문에, 검색 관련 기능 개발에 있어서는 필수적으로 알아두어야 하는 솔루션 중 하나이다. 성능적인 측면 외에도, ELK Stack 등 풍부한 추가 구성요소들을 통해 ETL 작업이나 admin 레벨의 monitoring, analytics 등을 지원하는 환경을 빠르게 구축할 수 있다.
이 글에서는 Elasticsearch를 database 관점에서 바라보고, 다음 내용들을 살펴볼 것이다.
- 기존 RDB들과 어떤 점이 다른가?
- 안정성이나 확장성이 있는가?
- 어떻게 사용해야 좋은 성능을 낼 수 있는가?
- data modeling은 어떤식으로 하면 좋은가?
1. Elasticsearch와 RDB의 차이
널리 사용되는 RDB와 비교를 통해 Elasticsearch의 특징에 대해 하나씩 알아보자.
1-1. 용어 차이
Elasticsearch는 기본적으로 NoSQL같은 형태로 data를 다루기 때문에, RDB와는 다소 상이한 용어들을 사용한다. 대략적으로 1:1 매칭을 해보면 다음과 같다.
| RDB | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Index | Analyze |
| Primary key | _id |
| Schema | Mapping |
| Physical partition | Shard |
| Logical partition | Route |
| Relational | Parent/Child, Nested |
| SQL | Query DSL |
이중 헷갈리기 쉬운 것들만 짚어보자. index는 최적화된 document들을 담은 저장 공간이며, 각 document는 데이터를 포함하고 있는 key-value pair로 이루어진 field들의 집합이다. type은 document에 포함되어야 하는 field들을 나타내는 것으로 일종의 테이블 스키마와 유사하다. 나머지 용어들에 대한 상세 개념은 뒤에서 설명하겠다.
1-2. 스키마 (Schema)
거의 모든 RDB는 엄격한 스키마를 요구한다. 테이블 생성 시점에 각 column의 이름과 데이터 타입을 지정하여 테이블 구조를 정의해야 한다. 한 번 테이블 구조가 정의되면, 변경 전까지 새로운 이름 혹은 다른 데이터 타입을 가진 column을 포함한 데이터를 record로 저장할 수 없다.
이에 비해, Elasticsearch는 스키마가 따로 존재하지 않는다. 즉, field와 field의 데이터 타입이 없어도 얼마든지 document를 저장할 수 있다. 하지만, 실제 운영 환경에서 사용하는 데이터는 스키마가 존재하고, 어느정도 체계화된 구조를 갖는다. 특정 type의 모든 document는 항상 공통 field 집합이 있다. 실제로, index type은 공통 field를 기반으로 생성된다, 즉, index에서 하나의 type을 가진 document들은 몇 가지 공통 field들을 공유한다.
Elasticsearch에서 document는 사용자 정의 field 외에도, 다음과 같이 내부적으로 시스템에 의해 정의된 field들을 내재하고 있다.
_id: RDB table의 primary key처럼 index 내 document의 고유 식별자다. 자동 생성되거나 사용자가 정의할 수 있다. (MongoDB의ObjectId, 즉,_id필드와 유사)_type: document의 타입을 포함한다._index: 도큐먼트의 index 이름을 포함한다.
1-3. 동작 방식: inverted index와 columnstore
기존 RDB에서는 data record 하나를 row로 저장한다.
row 하나에 블로그 문서 하나가 저장되며, column은 대략 id, text로 구성되어 있다고 가정해보자.
여러 문서들 중에서 특정 단어를 포함한 문서를 찾아야 한다면, RDB의 query는 어떤식으로 동작할까?
보통 SELECT문을 통해 문자열 포함 검색 (e.g. LIKE %text%)을 하게 될 것이다.
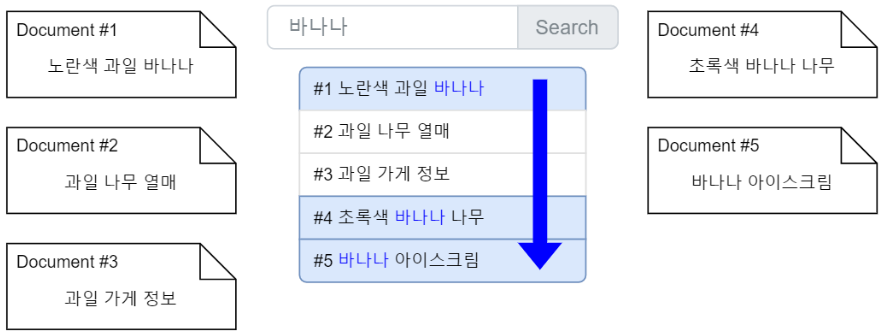
이 경우 시스템은 모든 문서를 한 번씩 훑으면서 substring search를 진행한다. 그렇다면 매번 사용자가 검색창에 검색어를 입력할 때마다 문서 수만큼의 iteration을 돌아야 한다. 검색 속도가 당연히 느릴 수 밖에 없다.
그렇다면 Elasticsearch는 어떤식으로 검색 작업을 수행할까? Elasticsearch는 문서를 입력받으면, 파싱 과정을 통해 문서를 단어 단위로 분리하여 저장한다. 또한, 대문자를 소문자로 변환하거나 유사어를 확인하는 등 추가적인 작업을 통해 text data를 저장한다.
덧붙이자면, Elasticsearch는 역 색인 (inverted index)이라고 하는 자료 구조를 사용하는데, 일반적인 문서들의 목차가 index라면, 키워드마다 내용을 찾아볼 수 있도록 돕는 목차가 inverted index라고 할 수 있다.

inverted index는 각 document에 등장하는 모든 고유 단어들을 리스트업하고, 해당 단어들이 등장하는 document들을 파악한다. Elasticsearch는 기본적으로 모든 field의 데이터를 인덱싱한다. 인덱싱된 field는 각각의 최적화된 자료구조를 사용한다. 텍스트 형식의 field는 inverted index에 저장되며, 숫자 혹은 위치 관련 field는 BKD tree에 저장된다. 또한, 내부적으로 데이터를 빠르게 분석하기 위해 columnstore를 사용한다. columnstore는 row 기반이 아닌 column 기반으로 쿼리를 처리해서 기존보다 N배 가량 더 빠르게 쿼리를 처리할 수 있는 기술이다. 이러한 기술들을 사용함에 따라 Elasticsearch를 통해 어떠한 데이터 타입에도 실시간 검색 및 분석을 빠르게 할 수 있다는 것을 알 수 있다.
1-4. 연산 종류에 따른 효율성: Elasticsearch는 RDB를 대체 가능한가?
RDB는 데이터 수정 및 삭제의 편의성과 속도 면에서 강점이 있다. 하지만, 다양한 조건의 데이터를 검색하고 집계하는 것에는 구조적인 한계가 존재한다. 앞서 언급했던 것처럼, 특정 단어 검색시 row 수만큼 확인을 반복하기 때문이다. 반면, 단어 기반으로 데이터를 저장하는 Elasticsearch는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 document를 검색할 필요가 없다.
그렇다면, Elasticsearch는 RDB를 완전히 대체할 수 있을까? 정답은 당연히 no다. 수정 및 삭제는 Elasticsearch에겐 내부적으로 굉장히 많은 리소스가 소요되는 작업이다. 쉽게 생각해보면, Elasticsearch라는 것은 결국 기존 RDB에서 data 구조를 바꾸고, 별도로 검색을 위한 인덱싱을 매우 heavy하게 하는 것이라고 이해할 수 있다. RDB에서도 인덱싱을 할 때마다 별도의 공간을 들여 b-tree, b+tree 등의 자료구조를 생성하고, 조회를 빠르게 돕는다. 이 인덱싱을 남용하면 database의 전체적인 성능저하가 발생하는 것은 당연지사이다. 앞서 언급했듯이 Elasticsearch는 기본적으로 모든 field를 인덱싱하므로 RDB로 따지면 인덱싱을 남용하고 있는 case라고 할 수 있다. Elasticsearch가 data 수정 및 삭제에 불리한 것은 어찌보면 자연스러운 결과다.
따라서, Elasticsearch는 RDB를 완전히 대체할 수 없다. 따라서 data 특성상 수정과 삭제가 빈번한 경우, RDB와 Elasticsearch의 영역을 나누어 설계해야 한다.
하지만, RDB와 공존하는 것이 매우 제한적인 상황에서 엘라스틱서치를 주로 사용해야 한다면 관계형 데이터 모델링을 고려해야 한다. 관계형 데이터 모델링에 대해서는 뒤에서 자세히 설명하도록 하겠다.
2. 확장성 및 고가용성 (Scalability & HA)
2-1. sharding
shard는 클러스터에서 index를 분배하고 단일 index의 document를 여러 노드로 분할해주는 개념이다. 노드마다 저장소, 메모리, 처리 용량이 다르기 때문에, 단일 노드에 저장할 수 있는 data의 양에는 제한이 있다. 따라서, shard를 활용하면 단일 index data를 나누어 클러스터에 분산 저장함으로써 scalability를 달성할 수 있다. sharding은 Elasticsearch에 내장된 고유 기능이며, 저장소 확장, 분산 및 병렬 처리 기능 수행에 그 목적이 있다.
기본적으로 모든 index는 Elastic에서 5개의 shard를 갖도록 구성된다. index 생성 시점에 data를 나눌 shard 수를 지정할 수 있다. 한 번 index를 생성하고 나면, shard 수는 변경할 수 없다.
그 이유는 무엇일까? Elasticsearch의 shard는 내부적으로는 Lucene의 index와 대응된다. Lucene은 단일 머신에서 동작하는 stand alone 검색엔진이고, shard마다 내부에 이러한 독립적인 루씬 라이브러리를 각각 갖고 있는 것이다. 따라서, shard 내부의 Lucene은 외부의 Elasticsearch가 다른 shard들과 더 큰 데이터셋을 가지고 인덱스를 구성하는 등의 상호작용을 하고 있다는 사실을 전혀 모른다. 이러한 상태에서 샤드의 개수를 변경한다는 것은, 각각의 Lucene이 갖고 있는 데이터를 모두 재조정하는 것과 동일한 의미가 된다.
이러한 특징 때문에 Elasticsearch에서는 shard 수 변경은 불가능하며, shard의 변경이 필요한 경우, 아예 새로운 index를 생성할 수 있도록 reIndex API를 제공한다.
POST _reindex
{
"source": {
"index": "old-index"
},
"dest": {
"index": "new-index"
}
}
다음 그림은 3개의 노드로 구성된 클러스터에서 5개의 샤드를 가진 index가 어떻게 분산되는지 보여준다.
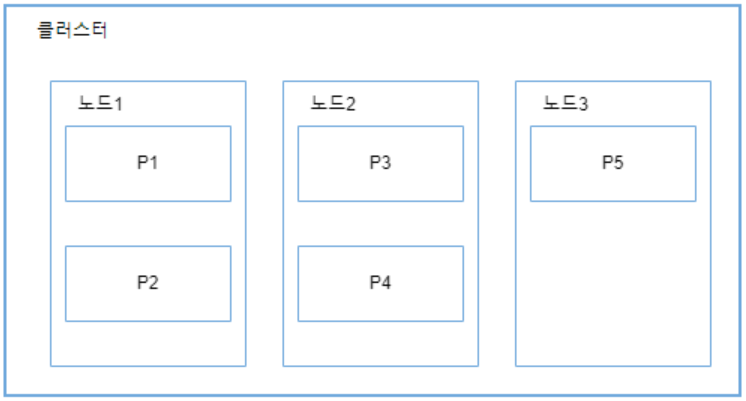
위 그림에서 각 shard는 index에 저장된 전체 data의 약 5분의 1을 포함한다. index에 쿼리를 수행하면 Elasticsearch는 각 shard에 모든 요청을 보낸 후, 결과를 통합한다.
2-2. replication
위 그림에서 클러스터에서 노드1에 장애가 발생한다면, 노드1에 위치한 shard1과 shard2에 저장된 data가 손실된다. 분산 시스템에서는 하드웨어 장애 상황에서도 문제없이 실행되어야 하므로, replica shard (이하 replica)를 통해 HA를 달성해야 한다. index의 각 shard는 0개 이상의 replica들을 가질 수 있다. 이때, replica의 원본이 되는 shard를 primary shard라고 지칭한다. 다음 그림은 primary shard마다 1개의 replica를 가지는 경우이다.
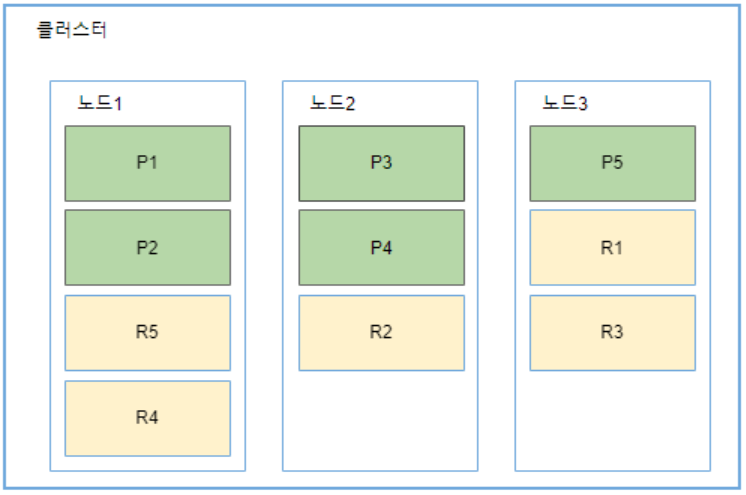
primary shard들은 녹색, replica들은 노란색으로 표시된다. 노드1에 장애가 발생하더라도, 노드2와 노드3에 대신 참조할 수 있는 모든 shard들이 준비되어 있다. replica들은 해당하는 primary shard에 장애가 발생하면, primary shard로 승격된다. replica들은 단순히 HA 보장 외에도, 쿼리 작업을 위해 사용될 수 있다. 다시 말해서, replica에서도 검색, 쿼리, 집계와 같은 읽기 연산이 수행될 수 있다. Elasticsearch는 보다 높은 성능 안정성을 위해, 쿼리 실행을 primary shard 또는 replica들이 위치한 클러스터 노드 전반에 걸쳐 적절히 분배한다.
3. 성능 최적화를 위한 shard 구성
3-1. primary shard 수와 크기를 정하는 기준
이론적으로는, primary shard의 수가 많을 수록 검색 성능이 좋아진다. 검색은 각 shard가 독립적으로 검색을 수행하고 나서 하나의 결과를 합쳐서 제공되므로, 다수의 shard로 분산될 수록 검색 속도도 비례해서 빨라진다. 병렬처리 개념으로 이해하면 된다. shard가 여러 노드로 나뉘어 있는 경우, 다수의 머신 파워를 동시에 사용할 수 있게 되므로, 클러스터의 읽기 성능을 높이는 좋은 수단이 된다.
하지만, 극단적으로 작은 크기의 shard들로 나누는 것은 바람직하지 않다. 클러스터에 존재하는 모든 shard는 마스터 노드에서 관리된다. 따라서, shard가 많아질 수록 마스터 노드의 부하도 증가한다. 마스터 노드의 부하로 인해 인덱싱과 검색 작업이 느려질 수도 있고, 메모리 문제가 발생할 가능성이 커진다. 그렇다면 shard 수를 줄이기 위해 shard 크기를 키우면 어떨까? 장애 발생 시 shard 단위로 데이터가 이동하기 때문에 shard의 크기가 너무 크면 복구 작업에 부정적인 영향을 미칠 수 있다. Elasticsearch에서는 shard 하나의 크기가 50GB를 넘지 않도록 권장한다.
3-2. replica 수 정하기
primary shard와 달리, replica의 수는 운영 중에 변경 가능하다. 일반적으로 장애 대응을 위해 최소 한 개 이상의 replica를 두는 것이 좋다. replica 수에는 다음과 같은 trade-off가 있다.
| replica 수 | 많음 | 적음 |
| 인덱싱 성능 | good | bad |
| 읽기 성능 | bad | good |
이유는 replica가 생성될 때도 primary shard와 마찬가지로 분산 읽기를 제공하기 위해 내부의 Lucene이 data segment를 생성하고, 인덱싱 관련 data를 전송하는 과정을 거쳐야 하기 때문이다. 이 때문에 많은 수의 replica는 인덱싱 성능을 떨어뜨리게 되고, 대신 더 많은 분산 처리를 가능케 하므로 읽기 성능은 올라가게 되는 것이다.
따라서, replica의 수는 색인 성능과 읽기 성능 중 어떤 것에 중점을 두느냐에 따라 결정하면 된다. replica 수는 자유롭게 변경이 가능하므로, 먼저 적은 수의 replica로 서비스를 시작하고, 필요에 따라 탄력적으로 조절하자. 단, HA를 위해 최소 replica 한 개는 유지하자.
3-3. ELK Stack 담당자들과 미팅 내용 정리
회사 프로젝트를 진행하면서, 운좋게도 B2B로 ELK Stack 셋업 및 운영을 지원해주시는 담당자 분들을 만나는 자리를 갖게 되었다. 미팅에서 질의응답 과정을 거치면서, 성능 및 운영 관련 내용 위주로 기억나는대로 정리해보겠다. 몇몇 내용들은 다른 글에서 더욱 상세하게 다루도록 하겠다.
- Elasticsearch의 data 노드가 총 3개라면, index마다 총 3개의 primary shard, 그리고 primary shard마다 1개의 replica가 가장 최적의 구성이다. (1개의 index 당 총 primary shard 3개, replica shard 3개)
- index template 기능을 활용하여 index pattern을 생성하면, index의 mapping 설정이 가능하다. 이를 통해 raw data를 파싱하여 원하는 mapping만 생성 가능하며, mapping 최적화를 통해 검색 속도 향상이 가능하다. (원하는 field들만 수집할 수 있다는 의미)
- index의 index lifecycle management 설정이 가능하다. index lifecycle 주기는 hot, warm, cold, 총 3개로 구성되어 있다. 오래된 index의 lifecycle을 hot -> warm -> cold로 변경하면 hot index에 대해 빠른 검색 속도 구현 가능하다.
- trace level을 설정하여 특정 log level 이상인 log만 저장 가능하다.
- index에 저장할 log를 정제할 때는 두 가지 방법을 많이 사용한다. 첫 번째는 Logstash를 사용하는 방법이다. 복잡한 로직으로 log 정제할 경우에 채택한다. 두 번째는 Elasticsearch 내의 ingest pipeline을 사용하는 방법이다. 간단한 로직으로 log 정제할 경우 채택한다.
- scale up 또는 scale out을 하는 시점은 전체 자원의 70% 이상 활용하는 시점 정도로 생각하면 된다.
- Elasticsearch document 용량 권장사항은 하나의 document당 100MB 이하이다.
- Kibana 외의 다른 dashboard들을 통합하고자 한다면, 특정 Kibana의 dashboard를 landing page로 구성하여 해당 page에 다른 솔루션 dashboard의 link를 첨부하는 식으로 구성한다.
- keyword field가 생성 안되는 오류가 있다면, mapping 개수가 너무 많거나, 해당 field의 text data가 지나치게 크진 않은지 점검해봐야 한다. 정확한 디버깅을 위해서는 파트너사에게 에러 log를 제공하여 해결해야 한다.
- Logstash 사양은 높을수록 좋다.
- data 노드 기준 디스크는 1 ~ 2TB 정도 사용하는 것을 권장한다. 3TB 이상이면 성능이 오히려 떨어질 수 있다.
- 시각화 쪽은 Kibana Lens를 제일 추천한다. TSVB는 디버깅이 좀 어렵다. Timelion은 여러 index pattern으로 그림 그리기가 가능해서 활용도가 높다.
- field를 keyword type으로 만드는 것은 aggregation 작업이 필요할 때만 쓰는게 좋다. 검색 작업용이라면 text type을 써야 한다.
- field가 너무 많으면 성능상 좋지 않다.
- Slow log 기능을 통해 임계값을 줘서 이상감지 같은 기능을 구현할 수 있다.
- ingest pipeline, index template, ILM 등은 필수적으로 숙지하는 것이 좋다.
- 검색속도는 shard의 size가 매우 중요하다. replica 수도 역시 검색 속도를 많이 좌우한다.
4. Elasticsearch의 데이터 모델링 방법
Elasticsearch도 결국에는 document를 담는 저장소이기 때문에, data 사이의 관계를 어떻게 표현해야 할지 애매한 경우가 많다. 상세한 내용들은 다른 글에서 자세히 다루도록 하고, 대표적인 방법론들에 대해서 간단하게 짚고 넘어가보자.
4-1. parent-child 모델링
join 데이터 타입을 통해 설계하는 방법이다. 하나의 index에서 parent와 child document 간에 join 타입으로 parent, child를 구분하고 parent와 child document에서 같은 라우팅 ID를 키로 제공하여 같은 shard에 위치하도록 설계한다. 이 방식은 전체 document에서 수정 및 삭제가 빈번하고 1:N 관계의 구조일 때 고려해 볼 만하다. 주의할 점은 라우팅 ID를 별도로 관리해야 한다는 점, 기존 쿼리에 비해 내부 연산이 많아 쿼리 자체에 부하가 있다는 점 (has_parent, has_child 쿼리), 그리고 aggregation 등 일부 쿼리 기능에 대한 제약이 있다는 점 등이 있다. join 자체가 무거운 연산이기 때문에, 되도록이면 뒤에 설명할 denormalization 방법을 채택하는 것이 권장된다. 다음 예시를 보자.
PUT my_index
{
"mappings": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
my_join_field라는 이름의 field에서 question과 answer가 parent-child 관계임을 명시한다.
4-2. nested 모델링
nested 데이터 타입을 활용해 설계하는 방법이다. 하나의 index에서 nested 데이터 타입을 선언하고 오브젝트 속성들을 정의하여 연속되도록, 마치 array처럼 배치하는 방식이다. 두 개 이상의 속성을 가진 오브젝트를 array 구조로 표현해야 할 때 고려해볼 수 있다. 다만, 이 방식을 사용할 경우 쿼리, 집계, 수정 작업을 할 때 주의해야 한다. nested array의 element마다 document가 하나씩 생성된다. 따라서, nested array가 포함된 문서 하나를 저장하면, 실제 내부적으로는 nested array size + 1만큼 document들이 저장된다. 따라서, 별도의 nested query를 작성해야 하고 수정 작업을 할 때 이러한 점을 고려해 디자인해야 한다. object와 nested의 차이에 대해서는 다른 글에서 다루도록 하겠다. 쿼리할 때 or와 and 관점에서 차이가 난다는 것 정도만 대략적으로 짚고 넘어가자. 다음의 예시를 보자.
{
"group": "admin",
"user": [
{
"userid: "iamsteve123",
"username": "steve"
},
{
"userid": "engel1004",
"username": "sally"
}
]
}
위처럼 user라는 field가 array 형식이라면, 내부적으로는 다음과 같이 저장된다.
{
"group": "admin",
"user.userid": [ "iamsteve123", "engel1004" ],
"user.username": [ "steve", "sally" ]
}
따라서, nested 타입을 지정하지 않고 object 타입으로 그대로 사용한다면, 쿼리시 or 연산 처리되어 원하지 않는 document들이 조회될 수 있다. 이런 경우 nested 타입으로 지정해주어야 and 연산처럼 동작한다.
4-3. application side join 모델링
primary key를 기준으로 관계있는 entity들을 서로 다른 document에 배치하여 app 측에서 키를 기준으로 join하여 처리하도록 하는 방식이다. 이 모델은 1:1 관계의 구조로 기존 쿼리와 aggregation을 그대로 사용해야 할 때 고려해볼 만 하다. Elasticsearch 쿼리를 그대로 사용 가능한 장점이 있으나, app 측에서 키 값을 기준으로 2회 이상 조회하여 별도로 가공해야 하므로, 페이징 및 정렬 처리에 주의해야 한다. 일반적으로 단순 조회 목적일 때 고려해 볼 만한 방법이다.
4-4. denormalization 모델링
data 전체를 비정규화하여 인덱싱하는 방법으로, 각 데이터의 중복을 허용하여 join이 필요하지 않도록 만든다. 이 기법은 join 연산 자체가 필요 없으며, 쿼리 시점에서 최고의 성능을 낼 수 있다는 점 때문에 잘 활용하면 최고의 모델이 될 수 있다. 다만, 다른 방식에 비해 데이터 크기가 증가되는 구조이기 때문에, 공통 field의 수정이 자주 발생하거나, 한정된 물리 서버로 구성해야 한다면 불리하다. 이 방법으로 모델링할 경우, 어떻게 data를 Elasticsearch 쪽으로 migration할 수 있을까? 세 가지 방법이 있다.
- Logstash JDBC Input 플러그인: JDBC 기반의 DBMS에서 직접 SQL join을 수행하여 비정형화된 데이터를 주기적으로 수집한다. 복잡한 관계의 data를 주기적으로 수집해야 할 때 사용하기 좋다.
- Logstash Translate Filter 플러그인: 바꾸려는 값들을 dictionary로 미리 정의하여 데이터가 들어올 때 dictionary에 정의된 값이 있으면 해당 값으로 매핑하여 처리한다. 특정 데이터 값만 필터링하거나, 가공해야 할 때 유용하다.
- Elasticsearch Ingest Pipeline Enrich 프로세서: lookup data를 Elasticsearch에 미리 저장하고 lookup의 조건을 policy로 정의해두는 방법이다. 이 policy에는 크게 lookup 인덱스 이름, match_field, enrich_field가 포함된다. data 소스가 특정 policy를 통해 들어올 경우, policy 조건에 따라 lookup된 data를 포함하여 인덱싱한다. join을 해야 하는 data를 유연하게 관리하고 유지해야 하는 경우 유용하다. 주의할 점은 policy 적용으로 생성된 enrich 데이터는 시스템 인덱스로 관리되고 인덱스를 자동으로 업데이트 하지 않기 때문에 lookup 데이터 변경 시 별도의 업데이트 작업을 해주어야 한다는 것이다. 엘라스틱 버전 7.5부터 사용할 수 있다.
5. References
https://docs.microsoft.com/ko-kr/sql/relational-databases/indexes/columnstore-indexes-overview
https://blog.yeom.me/2018/03/24/get-started-elasticsearch/
https://gintrie.tistory.com/46
https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
https://esbook.kimjmin.net/03-cluster/3.2-index-and-shards
댓글남기기